什么是 OpenGL?&创建三角形
注:本OpenGL文档来自https://learnopengl-cn.github.io,本版本有eick自己的理解,酌情查看
什么是 OpenGL?
OpenGL 是图形硬件的软件接口。此接口由大约 150 个不同的命令组成,可以使用这些命令指定生成交互式三维应用程序所需的对象和操作。
创建窗口
GLFW
GLFW 是一个专门针对 OpenGL 的 C 语言库,它提供了一些渲染物体所需的最低限度的接口。它允许用户创建 OpenGL 上下文,定义窗口参数以及处理用户输入,这正是我们所需要的。
构建 GLFW
CMake
CMake 是一个工程文件生成工具。
构建一个窗口
新建一个.cpp文件,引用 glad 和 glfw
接下来,创建main函数,在这个函数中,将会实例化 GLFW 窗口
首先,我们在 main 函数中调用 glfwInit 函数来初始化 GLFW,然后我们可以使用 flgwWindowHint 函数来配置 GLFW。
glfwWindowHint 函数的第一个参数代表选项的名称,我们可以从很多以GLFW_开头的枚举值中选择;第二个参数接受一个整型,用来设置这个选项的值。该函数所有的选项以及对应的值都可以在 GLFW’s window handling 这篇文档中找到。如果在编译中得到大量的_undefined reference_ (未定义的引用)错误,也就是说你并未顺利地链接 GLFW 库。
接下来,创建一个窗口对象,这个窗口对象存放了所有和窗口有关的数据,而且会被 GLFW 的其他函数频繁的使用到。
glfwCreateWindow 函数需要窗口的宽和高作为他的前两个参数。第三个参数表示这个窗口的名称。最后两个参数暂时忽略不计。这个函数会返回一个 GLFWwindow 对象,我们会在其他的 GLFW 操作中使用到。创建完窗口我们就可以通知 GLFW 将我们的窗口的上下文设置为当前线程的主上下文。
GLAD
在之前的教程中已经提到过,GLAD 是用来管理 OpenGL 的函数指针的,所以在调用任何 OpenGL 的函数之前我们需要初始化 GLAD。
我们给 GLAD 传入了用来加载系统相关的 OpenGL 函数指针地址的函数。GLFW 给我们的是 glfwGetProcAddress,它根据我们编译的系统定义了正确的函数。
视口
在开始渲染之前,我们必须告诉 OpenGL 渲染窗口的尺寸大小,即视口(viewport),这样 OpenGL 才能知道怎样根据窗口大小显示数据和坐标。我们可以通过调用 glViewport 函数来设置窗口的维度(Dimension):
glViewport 函数前两个参数控制窗口左下角的位置。第三个和第四个参数控制渲染窗口的宽度和高度(像素)。
我们实际上也可以将视口的维度设置为比 GLFW 的维度小,这样子之后所有的 OpenGL 渲染将会在一个更小的窗口中显示,这样子的话,我们也可以将一些其他元素显示在 OpenGL 视口之外。
OpenGL 幕后使用 glViewport 中定义的位置和宽高进行 2D 坐标的转换,将 OpenGL 中的位置坐标转换为你的屏幕坐标。例如,OpenGL 中的坐标(-0.5, 0.5)有可能(最终)被映射为屏幕中的坐标(200,450)。注意,处理过的 OpenGL 坐标范围只为-1 到 1,因此我们事实上将(-1 到 1)范围内的坐标映射到(0, 800)和(0, 600)。
当用户改变窗口的大小时,视口也应该被调整。我们可以对窗口注册一个回调函数,它会在每次窗口大小被调整的时候被调用。这个回调函数的原型如下:
这个帧缓冲大小函数需要一个 GLFWwindow 作为它的第一个参数,以及两个整数表示窗口的新维度。每当窗口改变大小,GLFW 会调用这个函数并填充相应的参数供你处理。
我们还需要注册这个函数,告诉 GLFW 我们希望每当窗口调整大小的时候调用这个函数:
当窗口被第一次显示的时候,framebuffer_size_callback 也被调用。对于是网络显示屏,width 和 height 都会明显比原输入值更高一点。
我们还可以将我们的函数注册到其他很多的回调函数中。比如说,我们可以创建一个回调函数来处理手柄输入变化,处理错误消息等。我们会在创建窗口之后,渲染循环初始化之前注册这些回调函数。
准备好你的引擎
我们可不希望智慧之一个图像之后我们的应用程序就立即退出并关闭窗口。我们希望程序在我们主动关闭它之前不断绘制图像,并能够接受用户输入。因此我们需要在程序中添加一个 while 循环,我们可以把它称之为渲染循环(Render Loop),它能在我们让 GLFW 推出前一直保持运行。下面几行的代码就实现了一个简单的渲染循环:
glfwWindowShouldClose 函数在我们每次循环的开始前检查依次 GLFW 是否被要求推出,如果是的话该函数返回 true 然后渲染循环便结束了,之后我们就可以关闭应用程序了。
glfwPollEvents 函数检查有没有触发什么事件(比如键盘输入、鼠标移动等)、更新窗口状态,并调用对应的回调函数(可以通过回调方法手动设置)。
glfwSwapBuffers 函数会交换颜色缓冲(它是一个存储着 GLFW 窗口每一个像素颜色值的大缓冲),它在这一迭代中被用来绘制,并且将会作为输出显示在屏幕上。
双缓冲(Double Buffer)
应用程序使用单缓冲绘图时可能会存在图像闪烁的问题。 这是因为生成的图像不是一下子被绘制出来的,而是按照从左到右,由上而下逐像素地绘制而成的。最终图像不是在瞬间显示给用户,而是通过一步一步生成的,这会导致渲染的结果很不真实。为了规避这些问题,我们应用双缓冲渲染窗口应用程序。前缓冲保存着最终输出的图像,它会在屏幕上显示;而所有的的渲染指令都会在后缓冲上绘制。当所有的渲染指令执行完毕后,我们交换(Swap)前缓冲和后缓冲,这样图像就立即呈显出来,之前提到的不真实感就消除了。
最后一件事
当渲染循环结束后我们需要正确释放/删除之前分配的所有资源。我们可以在main函数的最后调用glfwTerminate函数来完成。
输入
我们同样也希望能够在 GLFW 中实现一些输入控制,这可以通过使用 GLFW 的这几个输入函数来完成。我们将会使用 GLFW 的glfwGetKey函数,它需要一个窗口以及一个按键作为输入。这个函数将会返回这个按键是否正在被按下。我们将创建一个processInput函数来让所有的输入代码保持整洁。
这就给我们一个非常简单的方式来检测特定的键是否被按下,并在每一帧做出处理。
渲染
我们要把所有的渲染(rendering)操作放在渲染循环中,因为我们想让这些渲染指令在每次渲染循环迭代的时候都能被执行。
为了测试一切都正常工作,我们使用一个自定义的颜色清空屏幕。在每个新的渲染迭代开始的时候我们总是希望清屏,否则我们仍能看见上一次迭代的渲染结果(这可能是你想要的效果,但通常这不是)。我们可以通过调用glClear函数来清空屏幕的颜色缓冲,它接受一个缓冲为(Buffer Bit)来指定要清空的缓冲,可能的缓冲位有 GL_COLOR_BUFFER_BIT,GL_DEPTH_BUFFER_BIT 和 GL_STENCIL_BUFFER_BIT。由于现在我们只关心颜色值,所以我们只清空颜色缓冲。
glClearColor 函数是一个状态设置函数,而 glClear 函数则是一个状态使用的函数,它使用了当前的状态来获取应该清除为的颜色。
绘制三角形
记录三个词:
顶点数组对象:Vertex Array Object,VAO
顶点缓冲对象:Vertex Buffer Object,VBO
索引缓冲对象:Element Buffer Object,EBO 或 Index Buffer Object,IBO
在 OpenGL 中,任何事物都在 3D 空间中,而屏幕和窗口却是 2D 像素数组,这导致 OpenGL 的大部分工作都是关于把 3D 坐标转换为适应你屏幕的 2D 像素。3D 坐标转为 2D 坐标的处理过程是由 OpenGL 的图形渲染管线(Graphics Pipeline,指的是一堆原始图形数据途径一个输送管道,期间经过各种变化处理最终出现在屏幕的过程)管理的。图形渲染管线可以被划分为两个主要部分:第一部分把你的 3D 坐标转换为 2D 坐标,第二部分是把 2D 坐标转变为实际有颜色的像素。
2D 坐标和像素也是不同的,2D 坐标精确表示一个点在 2D 控件中的位置,而 2D 像素是这个点的近似值,2D 像素收到你的屏幕/窗口分辨率的限制。
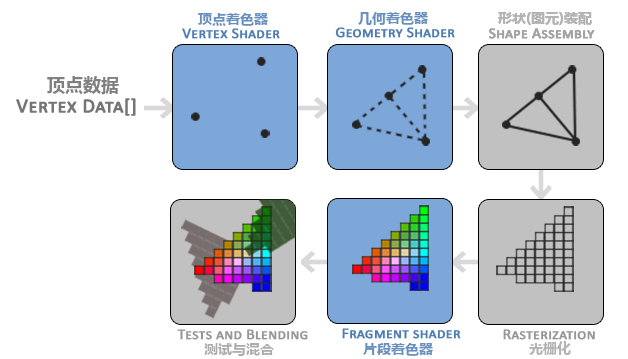
图形渲染管线接受一组 3D 图标,然后把他们转变为你屏幕上的有色 2D 像素输出。图形渲染管线可以被划分为几个阶段,每个阶段会把前一个阶段的输出作为输入。所有这些阶段都是高度专门化的(他们都有 i 个特定的函数),并且很容易并行执行。正是由于它们具有并行执行的特性,当今大多数显卡都有成千上万的小处理核心,他们在 GPU 上为每一个(渲染管线)阶段运行各自的小程序,从而在图形渲染管线中快速处理你的数据。这些小程序叫做着色器(Shader)。
有些着色器允许开发者自己配置,这就允许我们用自己写的着色器来替换默认的。这样我们就可以更细致的控制图形渲染管线中的特定部分了,而且因为他们运行在 GPU 上,所以他们可以给我们节约宝贵的 CPU 时间。OpenGL 着色器是用 OpenGL 着色器语言(OpenGL Shading Language,GLSL)写成的。
下图是一个图形渲染管线的每个阶段的抽象展示。要注意蓝色部分代表的是我们可以注入自定义的着色器部分。
图形渲染管线包含很多部分,每个部分都将在转换顶点数据到最终像素这一过程中处理各自特定的阶段。我们会概括性的解释一下渲染管线的每个部分,让你对图形渲染管线的工作方式有个大概了解。
首先,我们以数组的形式传递三个 3D 坐标作为图形渲染管线的输入,用来表示一个三角形,这个数组叫做顶点数据(Vertex Data);顶点数据是一系列顶点的集合。一个顶点(Vertex)是一个 3D 坐标的数据的集合。而顶点数据是用顶点属性(Vertex Attribute)表示的,它可以包含任何我们想用的数据,但是简单起见,我们还是假定每个顶点只由一个 3D 位置和一些颜色值组成的。
为了让 OpenGL 知道我们的坐标和颜色值构成的到底是什么,OpenGL 需要你去指定这些数据所表示的渲染类型。我们是希望把这些数据渲染成一系列的点?一系列的三角形?还是仅仅是一个长长的线?做出的这些提示叫做图元(Primitive),任何一个绘制指令的调用都将把图元传递给 OpenGL。这是其中的几个:GL_POINTS、GL_TRIANGLES、GL_LINE_STRIP。
图形渲染管线的第一个部分是顶点着色器(Vertex Shader),它把一个单独的顶点作为输入。顶点着色器主要的目的是把 3D 坐标转为另一种 3D 坐标,同时顶点着色器允许我们对顶点属性进行一些基本处理。
图元装配(Primitive Assembly)阶段将顶点着色器输出的所有顶点作为输入(如果是 GL_POINTS,那么就是一个顶点),并所有的点装配成指定图元的形状。
图元装配阶段的输出会传递给几何着色器(Geometry Shader)。几何着色器把图元形式的一系列顶点的集合作为输入,它可以通过产生新顶点构造出新的(或是其他的)图元来生成其他形状。
几何着色器的输出会被传入光栅化阶段(Resterization Stage),这里它会把图元映射为最终屏幕上的相应的像素,生成供片段着色器(Fragment Shader)使用的片段(Fragment)。在片段着色器运行之前会执行裁切(Clipping)。裁切会丢弃超出你的视图以外的所有像素,用来提升执行效率。
OpenGL 中的一个片段是 OpenGL 渲染一个像素所需的所有数据。
片段着色器的主要目的是计算哪一个像素的最终颜色,这也是所有 OpenGL 高级效果产生的地方。通常,片段着色器包含 3D 场景的数据(比如光照,阴影,光的颜色等等),这些数据可以被用来计算最终像素的颜色。
在所有对应颜色值确定以后,最终的对象将会被传到最后一个阶段,我们叫做 Alpha 测试和混合(Blending)阶段。这个阶段检测片段对应的深度(和模板(Stencil))值,用它们来判断这个像素是其他物体的前面还是后面,决定是否应该丢弃。这个阶段也会检查 alpha 值(alpha 值定义了一个物体的透明度)并对物体进行混合(Blend)。所以,即使在片段着色器中计算出来了一个像素输出的颜色,在渲染多个三角形的时候最后的像素颜色也可能完全不同。
可以看到,图形渲染管线非常复杂,它包含很多可配置的部分。然而,对于大多数场合,我们只需要配置顶点和片段着色器就行可。几何着色器是可选的,通常使用它默认的着色器就行了。
在现代 OpenGL 中,我们必须定义至少一个顶点着色器和一个片段着色器(因为 GPU 中没有默认的顶点/片段着色器)。
顶点输入
开始绘制图形之前,我们必须给 OpenGL 输入一些顶点数据。OpenGL 是一个 3D 图形库,所以我们在 OpenGL 中指定的所有坐标都是 3D 坐标(x、y、z)。OpenGL 不是简单的把所有的 3D 坐标变换为屏幕上的 2D 像素;OpenGL 仅当 3D 坐标在 3 个轴上都为-1.0 到 1.0 的范围内才处理它。所有的标准化设备坐标(Normalized Device Coordinates)范围内的坐标才会最终呈现在屏幕上(在这个范围外的坐标都不会显示)。
我们希望渲染一个·三角形,我们一共要指定三个顶点,每个顶点都有一个 3D 位置。我们会将它们以标准化设备坐标的形式(OpenGL 的可见区域)定义为一个float数组。
由于 OpenGL 是在 3D 空间中工作的,而我们渲染的是一个 2D 三角形,我们将它顶点的 z 坐标设置为 0.0.这样子的话三角形每一点深度(Depth)都是一样的,从而使他看上去像是 2D 的。
通常深度可以理解为 z 坐标,它代表一个像素在空间中和你的距离,如果离你远就可能被别的像素遮挡,你就看不到它了,它会被丢弃,以节省资源。
标准化设备坐标(Normalized Device Coordinates, NDC)
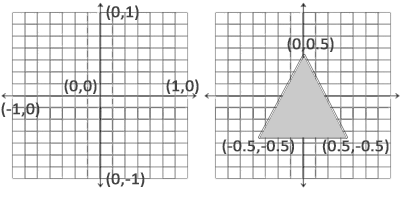
一旦你的顶点坐标已经在顶点着色器中处理过,它们就应该是标准化设备坐标了,标准化设备坐标是一个 x、y 和 z 值在-1.0 到 1.0 的一小段空间。任何落在范围外的坐标都会被丢弃/裁剪,不会显示在你的屏幕上。下面你会看到我们定义的在标准化设备坐标中的三角形(忽略 z 轴):
与通常的屏幕坐标不同,y 轴正方向为向上,(0, 0)坐标是这个图像的中心,而不是左上角。最终你希望所有(变换过的)坐标都在这个坐标空间中,否则它们就不可见了。
你的标准化设备坐标接着会变换为屏幕空间坐标(Screen-space Coordinates),这是使用你通过 glViewport 函数提供的数据,进行视口变换(Viewport Transform)完成的。所得的屏幕空间坐标又会被变换为片段输入到片段着色器中。
定义这样得顶点数据以后,我们会把它作为输入发送给图形渲染管线得第一个处理阶段:顶点着色器。它会在 GPU 上创建内存用于储存我们的顶点数据,还要配置 OpenGL 如何解释这些内存,并且指定其如何发送给显卡。顶点着色器接着会处理我们在内存中指定数量得顶点。
我们通过顶点缓冲对象(Vertex Buffer Objects, VBO)管理这个内存,它会在 GPU 内存(通常被称为显存)中储存大量顶点。使用这些缓冲对象得好处是我们可以一次性的发送一大批数据到显卡上,而不是每个顶点发送一次。从 CPU 把数据发送到显卡相对较慢,所以只要可能我们都要尝试尽量一次性发送尽可能多的数据。当数据发送至显卡得内存中后,顶点着色器几乎能立即访问顶点,这是个非常快的过程。
顶点缓冲对象是我们在 OpenGL 教程中第一个出现的 OpenGL 对象。就像 OpenGL 中的其他对像一样,这个缓冲有一个独一无二的 ID,所以我们可以使用 glGenBuffers 函数和一个缓冲 ID 生成一个 VBO 对象:
OpenGL 有很多缓冲对象类型,顶点缓冲对象的缓冲类型是 GL_ARRAY_BUFFER。OpenGL 允许我们同时绑定多个缓冲,只要他们是不同的缓冲类型。我们可以使用glBindBuffer函数把新创建的缓冲绑定到 GLARRAY_BUFFER 目标上:
此后,我们使用的任何(在 GL_ARRAY_BUFFER 目标上的)缓冲调用都会用来配置当前绑定的缓冲(VBO)。然后我们可以调用glBufferData函数,它会把之前定义的顶点数据复制到缓冲的内存中:
glBufferData是一个专门用来把用户定义的数据复制到当前绑定缓冲的函数。它的第一个参数是由目标缓冲的类型:顶点缓冲对象档期啊你绑定到 GL_ARRAY_BUFFER 目标上。第二个参数指定传输数据的大小(以字节为单位);用一个简单的sizeof计算出顶点数据大小就行。第三个参数是我们希望发送的实际数据。
第四个参数制定了我们希望显卡如何管理给定的数据。它由三种形式:
GL_STATIC_DRAW :数据不会或几乎不会改变。
GL_DYNAMIC_DRAW:数据会被改变很多。
GL_STREAM_DRAW :数据每次绘制时都会改变。
三角形的位置数据不会改变,每次渲染调用时都保持原样,所以它的使用类型最好是GL_STATIC_DRAW。如果,比如说一个缓冲中的数据将频繁被改变,那么使用的类型就是 GL_DYNAMIC_DRAW 或 GL_STREAM_DRAW,这样就能确保显卡把数据放在能够高速写入的内存部分。
现在我们已经把顶点数据储存在显卡的内存中,用 VBO 这个顶点缓冲对象管理。下面我们会创建一个顶点和片段着色器来真正处理这些数据。
顶点着色器
顶点着色器(Vertex Shader)是几个可编程着色器中的一个。如果我们打算做渲染的话,现代 OpenGL 需要我们至少一个顶点和一个片段着色器。我们会简要介绍一下着色器以及两个非常简单的着色器来绘制我们第一个三角形。
我们需要做的第一件事是用着色器语言 GLSL(OpenGL Shading Language)编写顶点着色器,然后编译这个着色器,这样我们就可以在程序中使用它了。下面是一个非常基础的 GLSL 顶点着色器的源代码:
可以看到,GLSL 看起来很像 C 语言,每个着色器都起始于一个版本声明。OpenGL 3.3 以及和更高版本中,GLSL 版本号和 OpenGL 的版本是匹配的,我们同样明确表示我们会使用核心模式。
下一步,使用in关键字,在顶点着色器中声明所有的输入顶点属性(Input Vertex Attribute)。现在我们只关心位置(Position)数据,所以我们只需要一个顶点属性。GLSL 有一个向量数据类型,它包含 1 到 4 个float分量,包含的数量可以从它的后缀数字看出来。由于每个顶点都有一个 3D 坐标,我们就创建一个vec3输入变量 aPos。我们同样也通过layout (location = 0)设定了输入变量的位置值(Location)你后面会看到为什么我们会需要这个位置值。
向量(Vector)
在图形编程中我们经常会使用向量这个数学概念,因为它简明地表达了任意空间中的位置和方向,并且它有非常有用的数学属性。在 GLSL 中一个向量有最多 4 个分量,每个分量值都代表空间中的一个坐标,它们可以通过
vec.x、vec.y、vec.z和vec.w来获取。注意vec.w分量不是用作表达空间中的位置的(我们处理的是 3D 不是 4D),而是用在所谓透视除法(Perspective Division)上。我们会在后面的教程中更详细地讨论向量。
为了设置顶点着色器的输出,我们必须把位置数据赋值给预定义的 gl_Position 变量,它在幕后是vec4类型的。在 main 函数的最后,我们将 gl_Position 设置的值会成为该顶点着色器的输出。由于我们的输入是一个 3 分量的向量,我们必须把它转换为 4 分量的。我们可以把vec3的数据作为vec4构造器的参数,同时把w分量设置为1.0f(我们会在后面解释为什么)来完成这一任务。
当前这个顶点着色器可能是我们能想到的最简单的顶点着色器了,因为我们对输入数据什么都没有处理就把它传到着色器的输出了。在真实的程序里输入数据通常都不是标准化设备坐标,所以我们首先必须先把它们转换至 OpenGL 的可视区域内。
编译着色器
我们已经写了一个顶点着色源码(储存在一个 C 的字符串中),但是为了能够让 OpenGL 使用它,我们必须在运行时动态编译它的源码。
首先要做的是创建一个着色器对象,注意还是用 ID 来引用的。所以我们储存这个顶点着色器为unsigned int,然后用 glCreateShader 创建这个着色器:
我们把需要创建的着色器类型以参数形式提供给 glCreateShader。由于我们正在创建一个顶点着色器,传递的参数是GL_VERTEX_SHADER。
下一步我们把这个着色器源码附加到着色器对象上,然后编译它:
glShaderSource 函数把要编译的着色器对象作为第一个参数。第二参数指定了传递的源码字符串数量,这里只有一个。第三个参数是顶点着色器真正的源码,第四个参数我们先设置为NULL。
你可能会希望检测在调用 glCompileShader 后编译是否成功了,如果没有成功的话,你还会希望知道错误是什么,这样你才能修复他们。检测编译时错误可以通过以下代码实现:
首先我们定义一个整型变量来表示是否成功编译,还定义了一个储存错误消息(如果有的话)的容器。然后我们用 glGetShaderiv 检查是否编译成功。如果编译失败,我们会用 glGetShaderInfoLog 获取错误消息,然后打印它。
如果编译的时候没有检测到任何错误,顶点着色器就被编译成功了。
片段着色器
片段着色器(Fragment Shader)是第二个也是最后一个我们打算创建的用于渲染三角形的着色器。片段着色器所做的是计算像素最后的颜色输出。
在计算机图形中颜色被表示为有 4 个元素的数组:红色、绿色、蓝色和 alpha(透明度)分量,通常缩写为 RGBA。当在 OpenGL 或 GLSL 中定义一个颜色的时候,我们把颜色每个分量的强度设置在 0.0 到 1.0 之间。比如说我们设置红为 1.0f,绿为 1.0f,我们会得到两个颜色的混合色,即黄色。这三种颜色分量的不同调配可以生成超过 1600 万种不同的颜色!
片段着色器只需要一个输出变量,这个变量是一个 4 分量向量,它表示的是最终的输出颜色,我们应该自己将其计算出来。我们可以用out关键字声明输出变量,这里我们命名为 FragColor.
编译片段着色器的过程与顶点着色器类似,只不过我们使用 GL_FRAGMENT_SHADER 常量作为着色器类型:
两个着色器现在都编译了,剩下的事情是把两个着色器对象链接到一个用来渲染的着色器程序(Shader Program)中。
着色器程序
着色器程序对象(Shader Program Object)是多个着色器合并之后并最终链接完成的版本。如果使用刚才编译的着色器我们必须把它们链接(Link)为一个着色器程序对象,然后在渲染对象的时候激活这个着色器程序。已激活着着色器程序的着色器将在我们发送渲染调用的时候被使用。
当链接着色器至一个程序的时候,它会把每个着色器的输出链接到下个着色器的输入。当输出和输入不匹配的时候,你会得到一个连接错误。
创建一个程序对象很简单:
glCreateProram 函数创建一个程序,并返回新创建程序对象的 ID 引用。现在我们需要把之前编译的着色器附加到程序对象上,然后用 glLinkProgram 链接它们:
就像着色器的编译一样,我们也可以检测链接着色器程序是否失败,并获取相应的日志。与上面不同,我们不会调用 glGetShaderiv 和 glGetShaderInfoLog,现在我们使用:
得到的结果就是一个程序对象,我们可以调用 glUseProgram 函数,用刚创建的程序对象作为它的参数,以激活这个程序对象:
在 glUseProgram 函数调用之后,每个着色器调用和渲染都会使用这个程序对象(也就是之前写的着色器)了。
在把着色器对象链接到着色器对象后,需要删除着色器对象,我们不需要它们了:
现在,我们已经把输入顶点数据发送给 GPU 了,并指示了 GPU 如何在顶点和片段着色器中处理它。就快要完成了,但还没结束,OpenGL 还不知道它该如何解释内存中的定点数据,以及它该如何将顶点数据链接到顶点着色器的属性上。我们需要告诉 OpenGL 怎么做。
链接顶点属性
顶点着色器允许我们指定任何以顶点属性为形式的输入。这使其具有很强的灵活性的同时,它还的确意味着我们必须手动指定输入数据的哪一个部分对应顶点着色器的哪一个顶点属性。所以,我们必须在渲染前指定 OpenGL 该如何解释顶点数据。
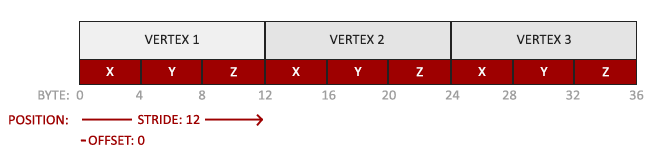
我们顶点缓冲数据会被解析成下面这样子:
位置数据被存储在 32 位(4 字节)浮点值
每个位置包含 3 个这样的值
在这 3 个值之间没有空隙(或其他值)。这几个值在数组中紧密排列(Tightly Packed)
数据中第一个值在缓冲开始的位置。
有了这些信息我们就可以使用 glVertexAttribPointer 函数告诉 OpenGL 该如何解析顶点数据(应用到逐个定点属性上)了:
glVertexAttribPointer 函数的参数非常多,所以我会逐一介绍它们:
第一个参数制定我们要配置的顶点属性。还记得我们在顶点着色器中使用
layout(location=0)定义了 position 顶点属性的位置值(location)吗?它可以把顶点属性的位置设置为 0。因为我们希望把数据传递到这一个顶点属性中,所以我们这里传入0。第二个参数指定顶点属性的大小。定点属性是一个
vec3,它是由 3 个值组成,所以大小是 3.第三个参数制定数据的类型,这里是 GL_FLOAT(GLSL 中
vec*都是由浮点数值组成的)。下个参数定义我们是否希望数据被标准化(Normalize)。如果我们设置为 GL_TRUE,所有数据都会被映射到 0(对于有符号型 signed 数据是-1)到 1 之间。我们把它设置为 GL_FALSE。
第五个参数叫做步长(Stride),它告诉我们在连续的顶点属性组之间的间隔。由于下个组位置数据在 3 个 float 之后,我们把步长设置为
3*sizeof(float)。要注意的是由于我们知道这个数据是紧密排列的(在两个顶点属性之间没有空隙)我们也可以设置为 0 让 OpenGL 决定具体步长是多少(只有当数值是紧密排列时才可用)。一旦我们有更多的顶点属性,我们就必须更小心地定义每个顶点属性之间的间隔,我们在后面会看到更多的例子(译注: 这个参数的意思简单说就是从这个属性第二次出现的地方到整个数组 0 位置之间有多少字节)。最后一个参数的类型是
void*,所以需要我们进行这个奇怪的强制类型转换。它表示位置数据在缓冲中起始位置的偏移量(offset)。由于位置数据在数组的开头,所以这里是 0。我们会在后面详细解释这个参数。
每个顶点属性从一个 VBO 管理的内存中获得它的数据,而具体从哪个 VBO(程序中可以有多个 VBO)获取则是通过在调用 glVertexAttribPointer 时绑定到 GL_ARRAY_BUFFER 的 VBO 决定的。由于在调用 glVertexAttribPointer 之前绑定的是先前定义的 VBO 对象,顶点属性 0 现在会链接到它的顶点数据。
现在我们已经定义了 OpenGL 该如何解释顶点数据,我们现在应该使用 glEnableVertexAttribArray,以顶点属性位置值作为参数,启用顶点属性;顶点属性默认是禁用的。自此,所有东西都已经设置好了;我们使用一个顶点缓冲对象将顶点数据初始化至缓冲中,建立了一个顶点和一个片段着色器,并告诉 OpenGL 如何把顶点数据链接到顶点属性上。在 OpenGL 中绘制一个物体,代码会像是这样:
每当我们绘制一个物体的的时候都必须重复这一过程。这看起来可能不多,但是如果有超过 5 个顶点属性,上百个不同物体呢。绑定正确的缓冲对象,为每个物体配置所有顶点属性很快就会变成一件很麻烦的事。有没有一些方法可以使我们把这些状态配置存储在一个对象中,并且可以通过绑定这个对象来恢复状态呢?
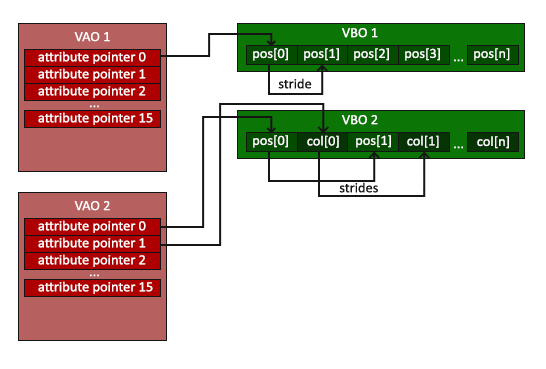
顶点数组对象
顶点数组对象(Vertex Array Object,VAO)可以像顶点缓冲对象那样被绑定,任何随后的顶点属性调用都会存储这个 VAO 中。这样的好处就是,当配置顶点属性指针时,你只需要将那些调用执行一次,之后再绘制物体的时候只需要绑定相应的 VAO 就行了。这使在不同顶点数据和属性配置之间切换变得非常简单,只需要绑定不同的 VAO 就行了。刚刚设置的所有状态都将存储在 VAO 中
OpenGL 的核心模式要求我们使用 VAO,所以它知道该如何处理我们的顶点输入。如果我们绑定 VAO 失败,OpenGL 会拒绝绘制任何东西。
一个顶点数组对象会储存以下内容:
glEnableVertexAttribArray 和 glDisableVertexAttribArray 的调用。
通过 glVertexAttribPointer 设置的顶点属性配置。
通过 glVertexAttribPointer 调用与顶点属性关联的顶点缓冲对象。
创建一个 VAO 和创建一个 VBO 很类似:
要想使用 VAO,要做的只是使用 glBindVertexArray 绑定 VAO。从绑定之后起,我们应该绑定和配置对应的 VBO 和属性指针,之后解绑 VAO 供之后使用。当我们打算绘制一个物体的时候,我们只要在绘制物体前简单的把 VAO 绑定到希望使用的设定上就行了。这段代码应该看起来像这样:
我们一直期待的三角形
要想知道绘制我们想要的物体,OpenGL 给我们提供了 glDrawArrays 函数,它使用当前激活的着色器,之前定义的顶点属性配置,和 VBO 的顶点数据(通过 VAO 间接绑定),来绘制图元。
glDrawArrays 函数第一个参数是我们打算绘制的 OpenGL 图源的类型。由于我们在一开始时说过,我们希望绘制的是一个三角形,这里传递 GL_TRIANGLES 给它。它第二个参数指定了顶点数组的起始索引,我们这里填0。最后一个参数指定我们打算绘制多少个顶点,这里是3(我们只从我们的数据中渲染一个三角形,它只有 3 个顶点长)。
现在尝试编译代码,如果弹出了任何错误,回头检查代码:编译通过则成功显示三角形。
索引缓冲对象
在渲染顶点这一话题上我们还有一个最需要讨论的东西-索引缓冲对象(Element BUffer Object,EBO,也叫 Index Buffer Object,IBO)。要解释索引缓冲对象的工作方式最好还是举个例子:假设我们不会再绘制一个三角形而是绘制一个矩形,我们可以绘制两个三角形来组成一个矩形(OpenGL 主要处理三角形)。这会生成下面的顶点的集合:
可以看到,有几个顶点叠加了。我们指定了右下角和左上角两次!一个矩形只有 4 个而不是 6 个顶点,这样就产生了 50%的额外开销。当我们包括上千个三角形的模型之后这个问题会更糟糕,这会产生一大堆浪费。更好的解决方案是只储存不同的顶点,并设定这些顶点的顺序。这样子我们只要储存 4 个顶点就能绘制矩形了,之后只要指定绘制的顺序就行了。如果 OpenGL 提供这个功能就好了,对吧?
很幸运,索引缓冲对象的工作方式正是这样的。和顶点缓冲对象一样,EBO 也是一个缓冲,它专门储存索引,OpenGL 调用这些顶点的索引来决定该绘制哪个顶点。所谓的索引绘制(Indexed Drawing)正是我们问题的解决方案。首先,我们先要定义(不重复的)顶点 ,和绘制出矩形所需的索引:
你可以看到,当时用索引的时候,我们只定义了 4 个顶点,而不是 6 个,下一步我们需要创建索引缓冲对象:
与 VBO 类似,我们先绑定 EBO 然后用 glBufferData 把索引复制到缓冲里。同样,和 VBO 类似,我们会把这些函数调用放在绑定和解绑函数调用之间,只不过这次我们把缓冲的类型定义为 GL_ELEMENT_ARRAY_BUFFER。
要注意的是,我们传递了 GL_ELEMENT_ARRAY_BUFFER 当作缓冲目标。最后一件要做的事是用 glDrawElements 来替换 glDrawArrays 函数,来指明我们从索引缓冲渲染,使用 glDrawElements 时,我们会使用当前绑定的索引缓冲对象中的索引进行绘制:
第一个参数指定了我们绘制的模式,这个和 glDrawArrays 的一样。第二个参数是我们打算绘制顶点的个数,这里填 6,也就是说我们一共需要绘制 6 个顶点。第三个参数是索引的类型,这里是 GL_UNSIGNED_INT。最后一个参数里我们可以指定 EBO 中的偏移量(或者传递一个索引数组,但是这是当你不在使用索引缓冲对象的时候),但是我们会在这里写 0。
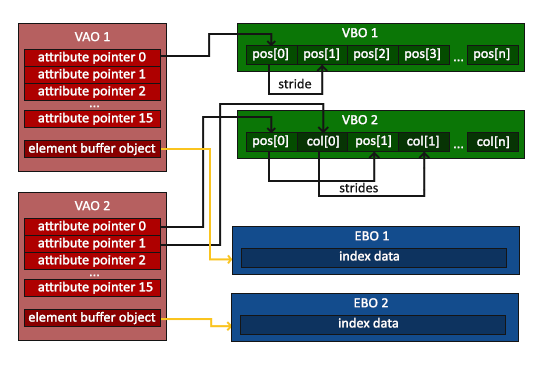
glDrawElements 函数从当前绑定到 GL_ELEMENT_ARRAY_BUFFER 目标的 EBO 中获取索引。这意味着我们必须在每次要用索引渲染一个物体时绑定相应的 EBO,这还有点麻烦。不过顶点数组对象同样可以保存索引缓冲对象的绑定状态。VAO 绑定时正在绑定的索引缓冲对象会被保存为 VAO 的元素缓冲对象。绑定 VAO 的同时也会自动绑定 EBO。
当目标是 GL_ELEMENT_ARRAY_BUFFER 的时候,VAO 会储存 glBindBuffer 的函数调用。这也意味着它也会储存解绑调用,所以确保你没有在解绑 VAO 之前解绑索引数组缓冲,否则它就没有这个 EBO 配置了。
最后的初始化和绘制代码现在看起来像这样:
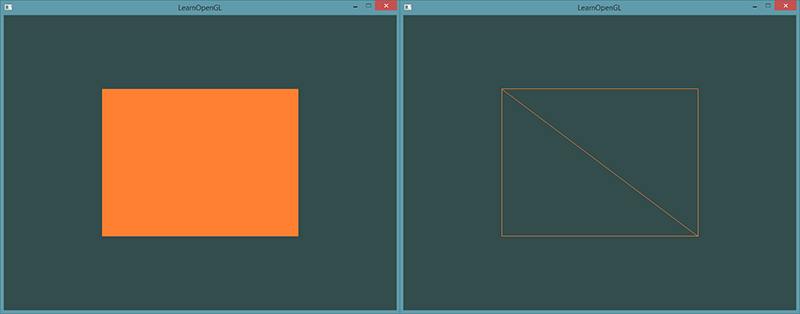
运行程序会获得下面这样的图片的结果。左侧图片看应该起来很熟悉,而右侧的则是使用线框模式(Wireframe Mode)绘制的。线框矩形可以显示出矩形的确是由两个三角形组成的。
线框模式(Wireframe Mode)
要想用线框模式绘制你的三角形,你可以通过
glPolygonMode(GL_FRONT_AND_BACK, GL_LINE)函数配置 OpenGL 如何绘制图元。第一个参数表示我们打算将其应用到所有的三角形的正面和背面,第二个参数告诉我们用线来绘制。之后的绘制调用会一直以线框模式绘制三角形,直到我们用glPolygonMode(GL_FRONT_AND_BACK, GL_FILL)将其设置回默认模式。
Last updated